













白話知識圖譜及其在CMDB中的應用
 2020-10-10
2020-10-10  by
by CMDB一直是運維建設的重點和難點。前段時間和北大同學一起探討有無可能利用知識圖譜相關的技術和方法重構CMDB?沒想到經過短短半年時間,北大同學就在這方面取得了重大進展,現已完成算法驗證,并發表國際學術論文《Mining Configuration Items From System Logs through Distant Supervision》。
由于學術論文比較晦澀難懂,所以我盡可能用樸實的文字將我們的工作成果和思考總結給大家做一個簡要匯報,歡迎批評指正。
本文主要包含兩塊內容:1、對知識圖譜的基本概念和思想起源做一個簡單的介紹;2、知識圖譜對CMDB的啟發以及我們的實踐成果。閱讀時間約20分鐘。
1. 什么是知識圖譜
你可以沒聽過知識圖譜,但一定聽過人工智能。人工智能可以簡單的分為兩大類:感知智能和認知智能。感知智能即視覺、聽覺、觸覺的感知能力。比如,自動駕駛汽車,就是通過激光雷達等感知設備和人工智能算法來實現感知智能的。比感知智能更厲害的是認知智能。認知智能通俗講是讓機器能理解會思考,能夠知識推理、因果分析等等。而知識圖譜,就是實現認知智能的基礎技術。
那么,知識圖譜究竟是什么呢?
別急,我們先看兩個典型的知識圖譜的應用場景。
第一個場景是智能搜索。Google于2012年在搜索引擎中引入知識圖譜技術,嘗試讓機器理解了人們輸入的搜索關鍵字是什么意思,有什么意圖,以便給出更加準確、豐富的搜索結果。
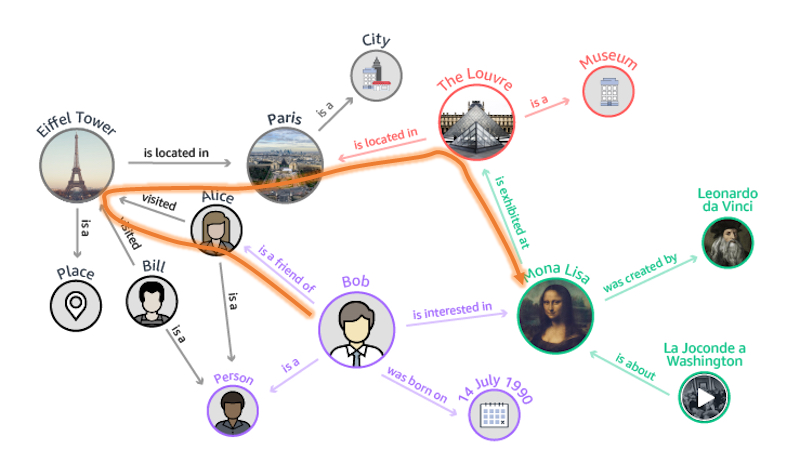
另一個場景是智能問答。比如,互聯網或知識庫中可能記錄了大量碎片化的信息和知識:

Bob想去看《蒙娜麗莎》,他很想知道自己有沒有朋友可能去看過?傳統的知識庫很難直接告訴你答案。但是如果將上面片段信息轉化成知識圖譜,就能讓電腦理解這些信息的關系,進而能直接給出答案:Bob的朋友Alice很可能去Louvre看了《蒙娜麗莎》。
上面兩個場景讓我們對知識圖譜有了感性認識,可知識圖譜是從哪兒來的呢?
2. 知識圖譜的思想起源
如果要探究知識圖譜的思想起源,則應將時間上溯到1922年英國哲學家維特根斯坦和他的《邏輯哲學論》。

在這本著作中,維特根斯坦主張世界的本質就是語言。因為語言是人類思想的表達,是整個文明的基礎,所以語言和世界是一體的。他從報紙上車禍的示意圖中領悟到,任何有意義的語句都應該能表達成由“實體和關系”組成的圖譜,而語句不斷積累疊加形成的巨大圖譜就是整個世界。
這一思想對哲學乃至數理邏輯都產生了劃時代的影響,為知識圖譜技術奠定了深刻而牢固的思想基因,揭示了知識圖譜的本質,即:用對象及其關系的語言符號來描述的現實世界的圖譜。
3. IT運維領域的知識圖譜
既然語言在現實世界如此重要。那么在IT的世界,機器之間又是用什么語言來交流呢?是日志。
日志是IT系統和設備在運行過程中自產生的數據,所以也稱為機器數據(Machine Data)。日志的信息量非常豐富,我們可以從日志中得知系統正在進行什么處理操作(系統日志),正在受理和發起哪些訪問請求(訪問日志),是否出現了異常狀況(錯誤日志)等等。但由于日志都是半結構性數據,中英文混合、結構復雜、內容多樣,在理解上較為困難,所以并沒有被有效利用,人們一般在排查故障時才會查看日志。
能否將這些機器語言轉換成IT運維的知識圖譜,從而實現類似智能根因分析和影響分析呢?比如,當要對某臺服務器做重啟時,知識圖譜就能告訴我們這臺服務器上現在正在運行哪些定時作業、這些作業又會影響哪些下游作業,這些下游作業屬于什么應用系統,這些應用系統是給哪些業務提供服務的。
咦,這不是CMDB在干的事兒嘛?沒錯,其實CMDB的本質就是IT運維領域的知識圖譜。而知識圖譜相關技術,也的確能夠幫助CMDB提升數據質量和使用體驗。當然本文主要探討第一個問題,因為CMDB最頭痛的還是數據質量。至于第二個問題以后會專門撰文闡述。
在探討第一個問題前,我們先簡單回顧一下傳統CMDB是如何構建的。
傳統構建CMDB的方式經歷了三個階段:
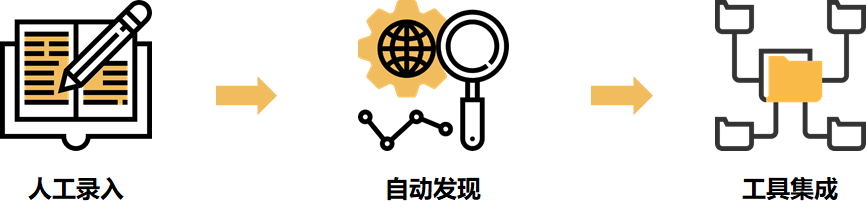
最早期是人工錄入,但工作量太大,且容易不準,因此很早就被廢棄。后來采用自動發現手段,通過命令從機器上采集配置數據,這種方法有一定成效,但也存在安全隱患、性能影響及可用性方面的風險,所以真正實踐起來困難重重。后來隨著自動化、云計算技術的發展,人們發現大部分配置數據根本不需要采集,直接從自動化、網管、云管等平臺中獲取即可。這種做法規避了自動發現帶來的安全隱患和性能風險,但也有局限性,就是CMDB的數據完全依賴這些第三方數據源,如果這些數據源不靠譜(比如覆蓋率或完整性不行,或壓根沒有接口供數)CMDB就歇菜了。而且大量數據接口的開發和維護也是頭痛的問題。
有沒有一種新的方法:讓維護配置數據的工作量更小、風險更低、覆蓋面更廣、泛化能力更強呢?
這就要靠知識圖譜了。我們認為,隨著日志數據的不斷細化、大數據存儲和處理能力的提升以及機器學習技術的日益發展,讓機器從海量日志中自動甄別和提取配置數據的條件正在逐漸成熟。因此,優锘科技正在與北大師生密切合作,將最新的算法和研究成果應用到CMDB中。
下面我將以網絡告警日志為例闡述我們的實現方法,首先來看一下整體流程:
流程總體上分為五個步驟,下面會逐一說明:
第一步:接入原始日志數據
本次實驗共接入9萬條網絡設備syslog數據。
第二步:日志聚類
所謂“物以類聚、人以群分”,人們會按照其品行、愛好而形成團體,這就是聚類。日志也一樣,想要分析海量日志數據,就要先對其聚類,從而搞清楚各種五花八門的日志背后是否有統一的模板。
最常用的聚類算法叫“頻繁項集”。項集指數據的集合,而頻繁項集就是從概率統計維度,從一堆貌似無規則的數據中找到最頻繁符合某項特征規則的數據集合。我們經常聽說的用戶消費行為分析、啤酒和尿布的故事等等就是頻繁項集算法的應用場景。只不過在日志場景下,聚類的特征規則不是日志的發生時間和地點,而是日志內容的相似度。
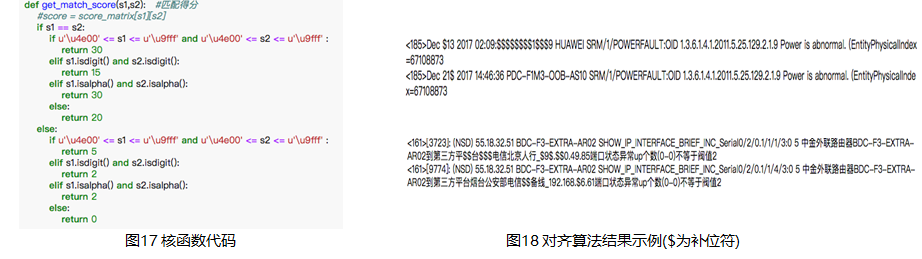
起初我們也采用頻繁項集算法對日志聚類,但效果不好。因為該算法要先對日志做“對齊匹配”(可簡單理解為結構化),然后才能進行聚類分析。可是原始日志是多語言混合結構的,其內容格式非常混亂且包含很多噪音,對全量日志做對齊匹配就會生成大量無效的日志模板。因此我們放棄了這個算法。
后來經過大量實驗,我們發現LDA算法的效果比較好。LDA是一種基于主題模型的算法,它有三大優勢:
** 不需要對齊匹配;**
** 是基于語義挖掘的主題模型;**
** 是一種無監督機器學習技術。**
第1項優勢避免了在全局開展無意義的對齊匹配所造成的大量無效日志模板。
第2項優勢是針對傳統的文檔匹配算法而言的。傳統方法(如TF-IDF等)在匹配文檔相似度時不考慮文字背后的語義關聯,僅通過查看兩個文檔共同出現的單詞的數量來判斷相似度,共同單詞越多就越相似。這就有問題了,比如,“他們的CMDB很成功”和“他們的配置管理超牛”,這兩句話雖然共同的單詞很少,但它們的語義非常相似。如果按傳統的方法判斷這兩個句子肯定相似度低,而LDA就會考慮文字背后的語義,進而給出高相似度結論。
第3項優勢提到LDA是一種無監督機器學習技術。什么是無監督?簡單的說就是不需要做大量標注它就能自己學。其實CMDB數據量就這么點兒,也沒法提供大量標注。用圖像識別這類監督型機器學習技術完全不靠譜。
下面是我們用LDA算法的實驗結果,將9萬條日志聚合成了23個分類(也可以理解為日志模板),正確率達到90%。比如下面四條日志都表達了control plane狀態異常這個主題,因此可歸為同一個日志模板。

第三步:識別變量
完成日志聚類后,我們就能以日志模板為單元分析其中的日志是否包含CI數據。從經驗上看,CI數據一般來自日志中的變量,因為日志中的常量一般都在描述當前正在干什么事兒,而變量一般描述誰在干或在干誰,這里的“誰”就是CI。所以,要識別潛在CI,就要先弄清楚哪些是變量。
但怎么從一大堆文本中識別變量呢?如果是人來做,肯定會逐條對比日志,如果發現它們在某個局部不一樣,那么這個局部就很可能是變量。類似的方法讓機器做就是史密斯-沃特曼算法(Smith-Waterman algorithm)。它是一種對局部序列比對(注意不是全局比對)的算法,最早用于基因序列比對,用來找出兩個序列中具有高相似度的基因片段。嗯?為什么找相似片段?不是要找不一致的片段嗎?沒錯,我們的做法是先把相似片段找到,然后將其剔除,剩下的就是不相似的片段了。這種方法也不是我們先創,它常常用來分析基因差異。舉個生活例子,鐘宏這幾年越來越禿,這是為什么呢?這肯定不是工作辛苦的原因,因為我就沒禿啊。如果用史密斯-沃特曼算法比對一下我倆的基因,剔除掉相似片段,找到不一致的片段,也許就能發現他早年謝頂的基因。

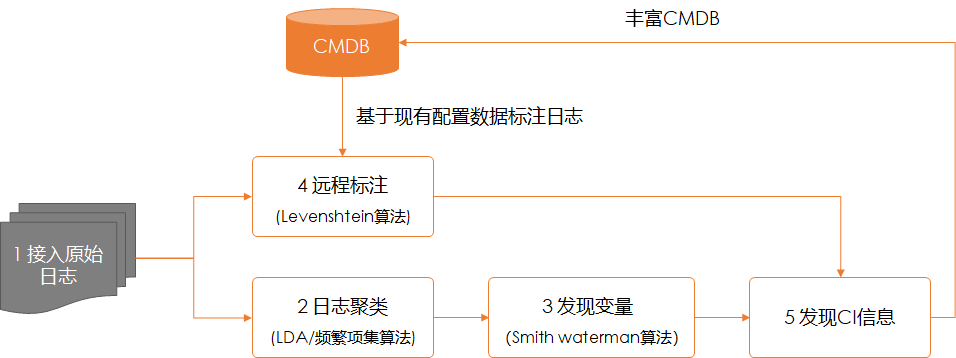
回到正題,由于原生的Smith-Waterman算法是針對基因序列比對的(原始核函數是G-T與A-C匹配則得分),而運用到運維日志比對上就需要額外定制核函數,增加漢語字符的匹配權重。
經過不斷的實驗和調參,我們獲得了比較滿意的結果,識別出了每個日志模板中的變量,后來又剔除掉日期、序號等日志片段后,剩下的大概率都是變量了。
現在我們知道哪些日志片段是變量,也知道其中必有CI,如果是你會怎么做?
你肯定會觀察這些變量值,然后去CMDB中核對,看它們與哪些CI屬性類似,進而判斷這些變量就是對應這些CI屬性。這項工作如果讓機器來做,就要用到遠程標注技術了。
第四步:遠程標注
遠程標注的目的,是讓機器能夠模擬人的行為,以CMDB數據做樣本,輔以機器學習算法,讓機器理解日志的語義,進而從中提取出CI數據。
最簡單的標注方法是嚴格匹配,即,將CMDB中的CI屬性值與日志進行嚴格匹配,能匹配的就給這段日志片段標注相應的CI屬性。但這種做法的效果并不好,因為CMDB的數據并不完整,而且數據質量不好,嚴格匹配根本匹配不出啥玩意來。為了提升泛化能力,我們采用了基于編輯距離的模糊匹配算法,即levenshtein算法。
所謂編輯距離是指由一個字串轉化成另一個字串最少的操作次數,這里說的操作包括包括插入、刪除、替換。次數越少,則編輯距離越短,字符串的相似度就越大。例如將eeba轉變成abac,需要經過下面三次操作:
** eba(刪除第一個e)**
** aba(將剩下的e替換成a)**
** abac(在末尾插入c)**
所以eeba和abac的編輯距離就是3。
當然,為了提升匹配效果,我們引入了伸縮控制機制,對于CMDB中的一個CI屬性中正教的CI屬性值x,按照其長度m將日志(長度為n)切分為n-m個子串yi;然后計算萊文斯坦比,即,levenshtein_ratio(x,yi),取最大x,設置閾值判定x是否與yi具有強相似性。實驗中閾值設置為0.8(1表示完全相似,0表示完全不相似),也就是說只要大于0.8,就證明CMDB中的某個CI屬性與該日志片段匹配上了。

完成遠程標注后,我們的工作就基本完成了,剩下的就是給機器喂大量的日志,然后坐等CMDB誕生就行了。不過有時候可能拉的不對,所以還需要一定的人工調整和過濾。不過人工介入的操作也會反饋給機器持續優化算法,所以理想情況下這種介入操作會越來越少。這種做法被稱為hybrid intelligence - 混合智能。
下一篇,我們將闡述一個使用知識圖譜技術自動構建CMDB的案例。
熱門標簽
熱門文章
 11.6K 13.3K 14.8K 14.3K
11.6K 13.3K 14.8K 14.3K


